Today was mostly a wrap-up session, but we were given some more time to explore topics of interest to us. I elected to spend some more time with RL, namely improving the epsilon-greedy algorithm explained in my last post. I decided to use the egreedy philosophy and apply it to a method of RL known as Q-Learning. Q-Learning is an algorithm where you take all the possible states of your agent, and all the possible actions the agent can take, and arrange them into a table of values (the Q-Table). These values represent the reward given to the agent if it takes that particular action while in that particular state. While they start at zero, the point of the algorithm is to accurately map and fill-in the Q-Table so that the most efficient (or close to it) series of actions is taken. The algorithm itself is pictured below

Most of these steps have been explained or are self-explanatory, however measuring reward is less intuitive. R is measured using what is known as the Bellman equation
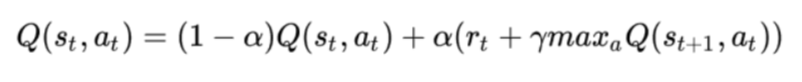
As you can see, the Q value at a certain point in the table (state, action) is updated based on the reward given and a few other parameters specified by the user such as the learning rate (alpha) and the discount rate (gamma, how much we weight the short and long-term rewards). The action choice part uses the epsilon-greedy strategy I described in my previous post, however unlike the last post, epsilon starts at 1 and slowly decays throughout the training process. This makes it so that the algorithm can explore its choices to the fullest extent early on but as it does so, it becomes more sure of the best choices. I tested this algorithm on the taxi cab problem using software called OpenAI Gym, and as expected the rewards increased over time while epsilon decreased. I have had so much fun at this internship, and I hope to continue to explore AI and reinforcement learning in the future. Thanks for reading!



